One may wonder why deep learning has only recently become recognized as a crucial technology though the first experiments with artificial neural networks were conducted in the 1950s.
Deep learning has been successfully used in commercial applications since the 1990s, but was often regarded as being more of an art than a technology and something that only an expert could use, until recently.
It is true that some skill is required to get good performance from a deep learning algorithm.
Fortunately, the amount of skill required reduces as the amount of training data increases.
The learning algorithms reaching human performance on complex tasks today are nearly identical to the learning algorithms that struggled to solve toy problems in the 1980s, though the models we train with these algorithms have undergone changes that simplify the training of very deep architectures.
The most important new development is that today we can provide these algorithms with the resources they need to succeed.
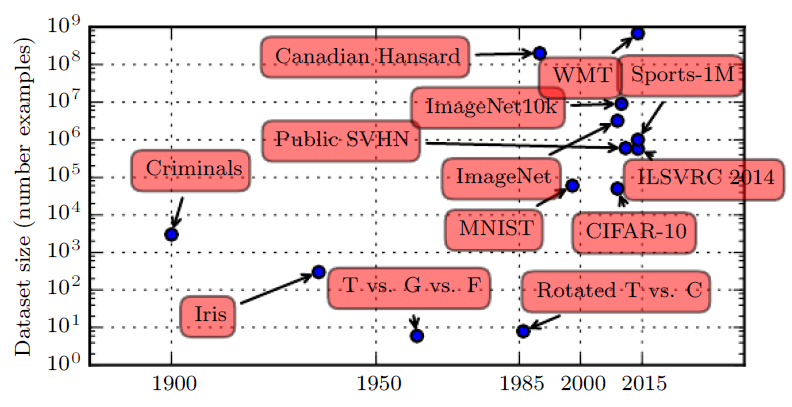
The figure below shows how the size of benchmark datasets has increased remarkably over time.
Dataset sizes have increased greatly over time.
- In the early 1900s, statisticians studied datasets using hundreds or thousands of manually compiled measurements (Garson, 1900; Gosset, 1908; Anderson, 1935; Fisher, 1936).
- In the 1950s through 1980s, the pioneers of biologically inspired machine learning often worked with small, synthetic datasets, such as low-resolution bitmaps of letters, that were designed to incur low computational cost and demonstrate that neural networks were able to learn specific kinds of functions (Widrow and Hoff, 1960; Rumelhart et al., 1986b).
- In the 1980s and 1990s, machine learning became more statistical in nature and began to leverage larger datasets containing tens of thousands of examples such as the MNIST dataset (shown in figure 1.9) of scans
of handwritten numbers (LeCun et al., 1998b).- In the first decade of the 2000s, more sophisticated datasets of this same size, such as the CIFAR-10 dataset (Krizhevsky and Hinton, 2009) continued to be produced.
- Toward the end of that decade and throughout the first half of the 2010s, significantly larger datasets, containing hundreds of thousands to tens of millions of examples, completely changed what was possible with deep learning.
These datasets included:
- the public Street View House Numbers dataset (Netzer et al., 2011),
- various versions of the ImageNet dataset (Deng et al., 2009, 2010a; Russakovsky
et al., 2014a),- the Sports-1M dataset (Karpathy et al., 2014).
- At the top of the graph, we see that datasets of translated sentences, such as IBM’s dataset constructed
from the Canadian Hansard (Brown et al., 1990) and the WMT 2014 English to French dataset (Schwenk, 2014) are typically far ahead of other dataset sizes.
This trend is driven by the increasing digitization of society.
As more and more of our activities take place on computers, more and more of what we do is recorded.
As our computers are increasingly networked together, it becomes easier to centralize these records and curate them into a dataset appropriate for machine learning applications.
The age of “Big Data” has made machine learning much easier because the key burden of statistical estimation—generalizing well to new data after observing only a small amount of data— has been considerably lightened.
As of 2016, a rough rule of thumb is that a supervised deep learning algorithm:
- will generally achieve acceptable performance with around 5,000 labeled examples per category,
- will match or exceed human performance when trained with a dataset containing at least 10 million labeled examples.
Working successfully with datasets smaller than this is an important research area, focusing in particular on how we can take advantage of large quantities of unlabeled examples, with unsupervised or semi-supervised learning.