It can be very difficult to extract such high-level, abstract features from raw data.
Many of these factors of variation, such as a speaker’s accent, can be identified only using sophisticated, nearly human-level understanding of the data.
When it is nearly as difficult to obtain a representation as to solve the original problem, representation learning does not, at first glance, seem to help us.
Deep learning solves this central problem in representation learning by introducing representations that are expressed in terms of other, simpler representations.
Deep learning allows the computer to build complex concepts out of simpler concepts.
The following figure shows how a deep learning system can represent the concept of an image of a person by combining simpler concepts, such as corners and contours, which are in turn defined in terms of edges:
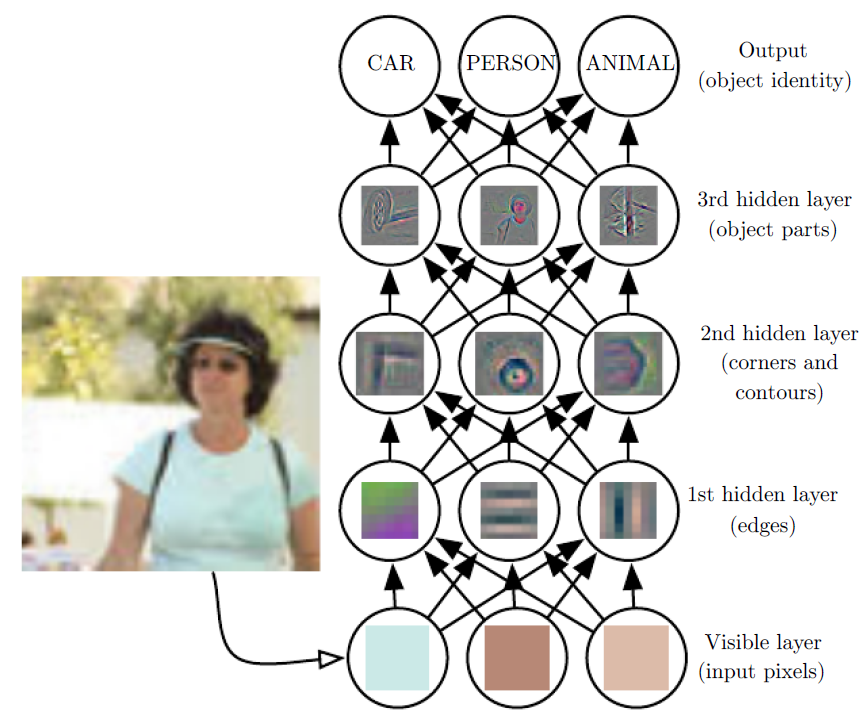
It is difficult for a computer to understand the meaning of raw sensory input data, such as this image represented as a collection of pixel values.
The function mapping from a set of pixels to an object identity is very complicated.
Learning or evaluating this mapping seems insurmountable if tackled directly.
Deep learning resolves this difficulty by breaking the desired complicated mapping into a series of nested simple mappings, each described by a different layer of the model.
The input is presented at the visible layer, so named because it contains the variables that we are able to observe.
Then a series of hidden layers extracts increasingly abstract features from the image.
These layers are called “hidden” because their values are not given in the data; instead the model must determine which concepts are useful for explaining the relationships in the observed data.The images here are visualizations of the kind of feature represented by each hidden unit.
- Given the pixels, the first layer can easily identify edges, by comparing the brightness of neighboring pixels.
- Given the first hidden layer’s description of the edges, the second hidden layer can easily search for corners and extended contours, which are recognizable as collections of edges.
- Given the second hidden layer’s description of the image in terms of corners and contours, the third hidden layer can detect entire parts of specific objects, by finding specific collections of contours and corners.
- Finally, this description of the image in terms of the object parts it contains can be used to recognize the objects present in the image.