What is Machine Learning?
The definition I have come up with for Machine Learning is as follows…
machine learning is using data to detect patterns
It involves 2 key concepts:
- Using statistics and math optimize this process
- The optimization process is referred to as training
Here’s the big kicker that will likely make some people unhappy.
ML and AI are the same thing.
Nothing is New
What I find really interesting about ML is that none of the concepts are particularly new.
The algorithms that are currently en vogue have been around for a while.
The major change is that computers have become
- faster
- cheaper
- more readily available
These 3 things, combined with the ever expanding and easy to use machine learning libraries such as Tensorflow have made machine learning accessible to more people.
How Machine Learning Works
Machine learning uses different algorithms to detect patterns.
These algorithms all do the same thing: they take input data and use it to produce weights.
These weights can then be used to make predictions about future observations of data in the same format.One of the big advances in the past few years is that we (the humans) have come up with ways to relax the strict conditions by which these algorithms are able to accept input.
Despite this, almost all algorithms still need to be fed clean, consistent tabular data in order to be effective.Now when these algorithms train or calibrate, what they’re really doing is finding the minimum distance between a set of points. This is much easier illustrated than typed.
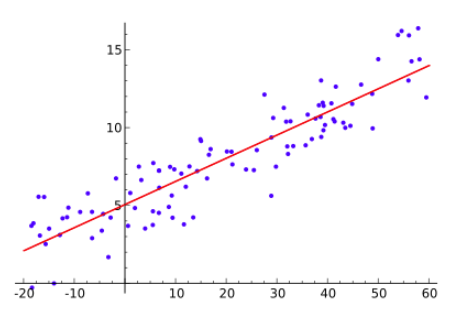
Take the image above as an example. This is a classic simple linear regression.
- The blue points are the data we want to predict.
- The red line is the “line of best fit” that our machine learning algorithm has calculated as the best way to characterize this dataset.
You can then use that line to make predictions about future observations.
Classification and Regression
The overwhelming majority of machine learning tasks break down into 2 categories:
- regression — predicting a value (such as price or time to failure)
- classification — predicting the category of something (dog/cat, good/bad, wolf/cow)
In regression, you’re trying to calculate a line that will be “in the middle” of all of your data points (as seen above).
In classification, you’re trying to calculate a line that will “separate the categories” of your data points.
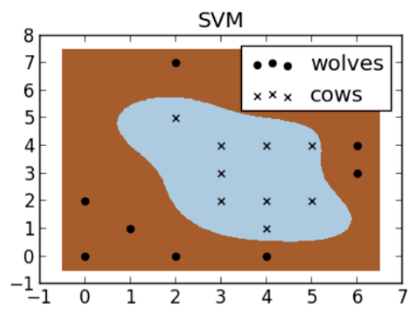
What is «SVM» («support-vector machine»)?
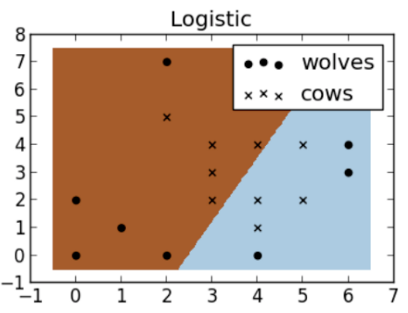
What is «logistic regression»?
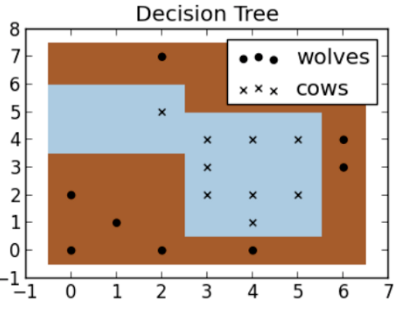
What is a «decision tree» in machine learning?
Algorithms
Different algorithms can use different shapes, numbers, and types of lines to calculate the middle line or separating line.
For instance, in the wolf and cow example above, there are 3 different algorithms beings used to separate each category.
- As you can see, the SVM method is non-linear, meaning it doesn’t have to use straight lines.
- While the logistic method, which is linear, can only separate points by using a straight line.
- And then behind door is a decision tree which uses a set auto-generated rules in order to separate the categories.
Overfitting
So why wouldn’t you always just use the most sophisticated method?
Sometimes your model can be too clever.
I know these seem like a step backwards but it’s true.
Your AI can be too good at understanding the dataset you’re showing it.
As a result, it’s not general enough to make predictions on future observations.
towardsdatascience.com/machine-learning-for-people-who-dont-care-about-machine-learning-4cf0495dee2c