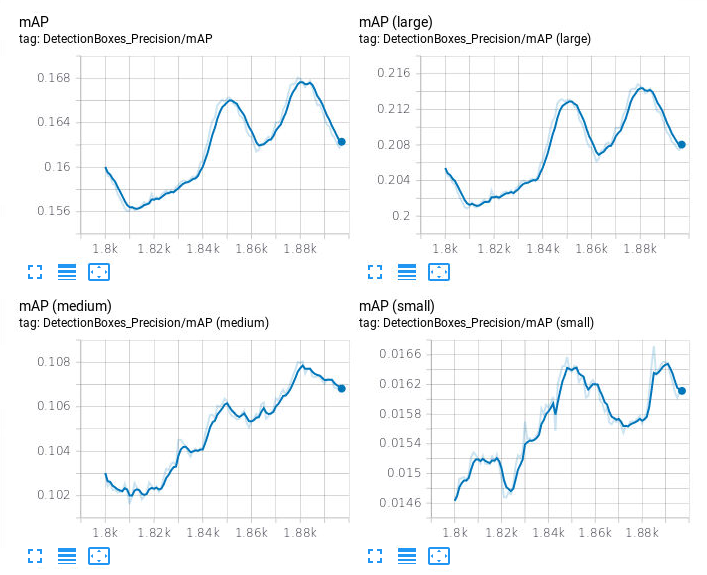
It could be because of this:
Typically with quantization, a model will train with full precision for a certain number of steps before switching to quantized training.
Thedelaynumber above tells ML Engine to begin quantizing our weights and activations after 1800 training steps.
But I have never set it to 1800 explicitly, and default it 500000: