Learning rate is a hyperparameter that controls how much we are adjusting the weights of our network with respect the loss gradient.
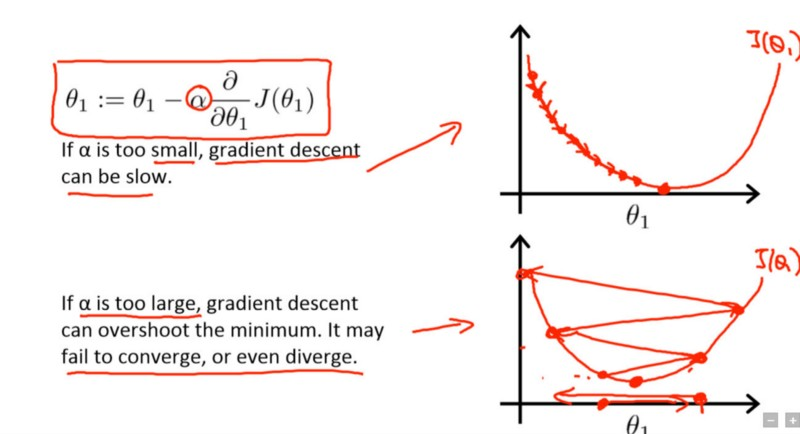
The lower the value, the slower we travel along the downward slope.
While this might be a good idea (using a low learning rate) in terms of making sure that we do not miss any local minima, it could also mean that we’ll be taking a long time to converge — especially if we get stuck on a plateau region.The following formula shows the relationship:
new_weight = existing_weight — learning_rate * gradient
Typically learning rates are configured naively at random by the user.
At best, the user would leverage on past experiences (or other types of learning material) to gain the intuition on what is the best value to use in setting learning rates.As such, it’s often hard to get it right.
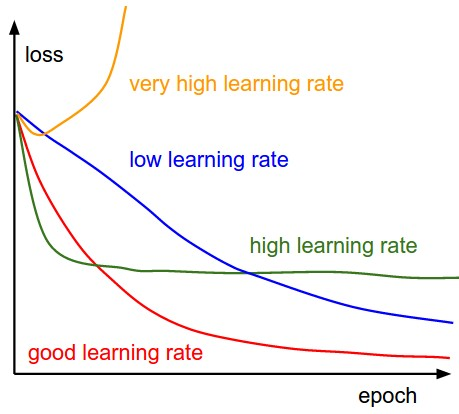
The below diagram demonstrates the different scenarios one can fall into when configuring the learning rate:
Furthermore, the learning rate affects how quickly our model can converge to a local minima (aka arrive at the best accuracy).
Thus getting it right from the get go would mean lesser time for us to train the model.
Less training time, lesser money spent on GPU cloud compute.